
 交易智能
交易智能
 销售团队智能
销售团队智能
 市场智能
市场智能
 CRM系统
CRM系统
 呼叫中心
呼叫中心
 在线会议平台
在线会议平台
 IM通讯
IM通讯






 企业服务
企业服务
 消费医疗
消费医疗
 教育
教育
 汽车
汽车
 房地产
房地产
 金融
金融
 销售人员
销售人员
 销售管理
销售管理
 交易跟进
交易跟进
 培训辅导
培训辅导
 全部
全部
 白皮书
白皮书
 销售会话智能
销售会话智能



销售部的培训革新:AI 陪练助力医药代表精准突破业务瓶颈

在医药行业加速数智化转型的当下,医药代表作为连接企业与临床的关键角色,其培训体系却仍受困于传统模式的束缚。工业和信息化部消费品工业司 2024 年发布的行业报告显示,超过 70% 的医药企业存在培训内容更新跟不上产品迭代速度的问题,这种滞后性正在逐渐影响企业的市场竞争力。
从事医药培训管理工作 8 年的张经理,对此深有感触:“我们去年推出一款新型降糖药时,从临床数据整理到课件制作花了近一个月,等培训完代表,竞品已经先一步完成了重点医院的布局。” 这种困境并非个例,具体来看,传统培训主要面临以下难题:

1.知识传递:记得慢、忘得快,还难按需匹配
医药产品的专业知识复杂且严谨,从成分机制到临床数据,每一项都需要代表精准掌握。但线下集中培训的 “填鸭式” 模式,往往导致知识吸收效果不佳。医药经济报 2024 年行业调研数据显示,线下课程结束 15 天后,代表对核心数据的记忆留存率仅为 32%,很多关键信息在实际拜访中根本无法准确复述。
更棘手的是,不同区域、不同客户类型的需求差异极大:
一线城市三甲医院:医生更关注循证医学证据,对临床试验数据的严谨性要求高
基层医疗机构:医生更在意用药安全性和价格,需重点讲解性价比优势
社区卫生服务中心:医生关注药物的便捷性和患者依从性,需简化专业术语表述
但目前 92% 的企业仍采用 “一刀切” 的培训模式,无法满足这种个性化需求。
2.实战训练:想练不敢练,效果难衡量
学术推广中的沟通场景充满不确定性,比如医生突然提出的不良反应疑问、医保政策解读需求,都需要代表快速响应。但传统培训中,实战练习机会少得可怜 —— 每位代表年均仅能参与 4-6 次资深带教,更多时候只能靠自己 “摸索试错”。
“直接跟医生沟通时,最怕说错话。” 刚入职半年的医药代表小李坦言,“有次我误把‘辅助治疗’说成‘一线治疗’,幸好医生及时指正,不然可能会有合规风险。” 这种对合规风险的担忧,让很多代表在实际沟通中变得小心翼翼,而依赖人工观察的评估方式,又存在明显局限:
评估维度单一:多聚焦 “话术流畅度”,忽略 “专业准确性”“合规性” 等关键维度
主观因素影响大:不同讲师的评判标准存在差异,难以形成统一结论
反馈滞后:通常在培训结束后 1-2 周才给出评估结果,错过即时改进时机
深维智信 Megaview AI 陪练如何破局?技术架构背后的实用价值
面对这些困境,深维智信 Megaview AI 陪练作为行业先进的销售 AI 赋能平台,逐渐进入医药企业的视野。它并非简单的 “技术堆砌”,而是通过大模型与垂直领域技术的融合,依托自主研发的 MegaAgents 应用架构与 MegaRAG 领域知识库解决方案,构建起 “知识传递 – 场景模拟 – 效果评估” 的完整闭环,切实解决培训中的实际问题,还能提供 AI 建课、AI 演讲、AI 点评等新一代智能培训体验。

1.三层技术底座:兼顾专业度与实用性
深维智信 Megaview AI 陪练的技术架构以自然语言处理(NLP)为核心,搭配语音识别(ASR)、智能体动态增强等技术,形成了基础模型层、场景引擎层、评估系统层的三层结构。这种结构既保证了医学知识的专业性,又能快速响应实际培训需求。
(1)基础模型层:行业定制,精准理解专业表述
采用 8B 参数的行业定制大模型,通过对通用大模型进行 SFT(有监督微调) 和 RLHF(基于人类反馈的强化学习) ,重点强化医学领域的语义理解能力 —— 前者通过标注的医药对话数据优化模型输出,后者结合资深培训师的反馈调整模型决策偏好,确保回答既专业又贴合实际沟通场景。其中,MegaRAG 领域知识库解决方案发挥关键作用,能高效整合药品说明书、临床指南等专业资料,构建结构化知识库:
医学术语识别准确率:达到 96.7%,能精准区分 “药代动力学” 与 “药效动力学”、“客观缓解率” 与 “疾病控制率” 等易混淆概念
上下文关联能力:可理解 “该药物与某竞品的代谢途径差异” 等复杂问句,避免机械匹配关键词
数据更新频率:每季度通过增量预训练纳入最新临床指南、药品说明书,无需全量重训即可更新知识,降低技术成本
(2)场景引擎层:动态生成,模拟真实沟通场景
依托 TTS(语音合成)与数字人技术,结合 Prompt Engineering(提示工程) 构建动态对话生成系统 —— 这正是深维智信 Megaview AI 陪练动态场景生成引擎的核心能力,能依据医药行业特性、不同药品属性和销售场景,设计精准的提示词模板,生成逼真的模拟环境与案例,创建虚拟客户供代表进行 1v1 实战演练:
场景覆盖广度:支持 12 类核心沟通场景,包括科室会宣讲、门诊拜访、不良反应解答、医保政策解读等,还可延伸至需求挖掘、客户异议、竞品对比等销售全场景
人物画像丰富度:每个场景内置 3-5 种客户画像,如严谨型专家、务实型医师、疑虑型护士等,通过不同提示词模板模拟差异化沟通风格
对话连贯性:多轮对话连贯性评分达 4.8/5.0,能根据代表的回答调整追问方向,避免 “答非所问”

(3)评估系统层:多维分析,客观呈现能力短板
基于多标签分类模型和语义相似度计算技术,构建经过 16 维度指标体系训练的评估系统 —— 前者用于识别代表回答中的 “合规风险”“知识缺失” 等标签,后者用于比对回答与标准话术的匹配度,实现对会话内容的深度解析。借助 MegaAgents 应用架构的协同能力,系统能实时收集和分析陪练过程中的数据,多维评估销售能力:
评估维度:涵盖产品知识、沟通逻辑、合规性、应变能力、术语准确性等
结果一致性:评估结果与人工一致性达 89%,减少主观因素干扰
反馈速度:会话结束后 30 秒内生成反馈和建议,支持即时改进,还能提供个性化辅导,使培训更具针对性和科学性
2.三大功能模块:从 “学” 到 “练” 再到 “评” 的全流程覆盖
(1)知识内化:碎片化学习,随用随查
系统通过知识图谱将药品说明书、临床研究数据等专业内容拆解成 200-300 字的知识单元 —— 以 “药物成分 – 适应症 – 用法用量 – 不良反应” 为核心节点构建关联关系,这一过程依托 MegaRAG 领域知识库解决方案实现高效数据整合,代表查询时不仅能获取答案,还能看到相关知识的逻辑关联,加深理解。
小李就经常用这个功能:“上次准备拜访一位心血管科医生,我不确定我们的药物与某竞品的代谢途径差异,在 Megaview 系统里输入问题,0.8 秒就得到了对比结果,还标注了数据来源是某 III 期临床试验的 NCT 编号,跟医生沟通时特别有底气。”
该模块的核心优势包括:
检索速度快:基于向量数据库实现语义检索,平均响应时间 0.8 秒,支持多轮追问
信息溯源清晰:所有答案均标注数据来源,如临床试验编号、指南发布机构等
内容形式灵活:支持文字、图表、短视频等多种形式呈现,适配不同学习习惯
(2)场景模拟:高保真实战,错了能重来
依托技术底座的场景引擎,结合 Few-Shot Learning(少样本学习) 技术,Megaview 能快速适配新的产品场景 —— 只需提供 3-5 个该产品的沟通案例,模型就能通过少样本学习掌握核心推广要点,为代表提供高保真的实战练习环境。更贴心的是,系统的话术提示准确率达 85.23%,能实时纠正专业术语错误,像新人上岗培训、高压测试、价格谈判等场景,都能通过虚拟客户 1v1 演练提升代表应对能力:
“有次我在模拟讲解肿瘤药物时,把‘客观缓解率’说成了‘总生存率’,系统马上弹出提示,还附上了正确定义,这种即时纠错比事后复盘管用多了。” 小李分享道。该模块的关键功能包括:
实时纠错:通过关键词匹配和语义校验识别错误表述(如术语混淆、数据夸大),即时弹出提示框,附带正确内容
场景难度调节:支持从 “基础版”(仅核心问题)到 “进阶版”(含突发疑问)的难度切换,满足不同阶段代表的训练需求
会话回放:支持录制模拟过程,方便代表复盘自己的沟通逻辑和话术问题
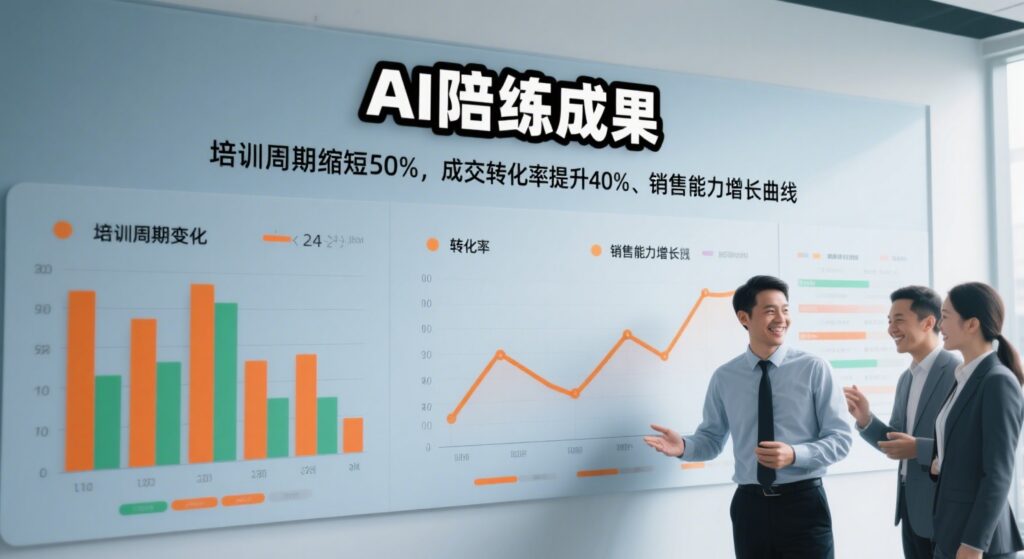
(3)能力评估:数据化画像,短板清晰可见
系统会通过分析会话内容,从 16 个维度生成评估报告。比如在某次肿瘤药物推广模拟中,系统通过实体识别技术发现张经理团队的几位代表都忽略了 “药物相互作用” 相关实体的讲解,随即推送了相关学习资料,还在团队看板上标注了这一能力短板,方便培训部门针对性调整计划。这种评估不仅能定位个人短板,还能将优秀销售的沟通逻辑、话术技巧转化为可复制的数据资产,供团队学习:
评估报告的呈现形式兼顾 “个人” 与 “团队”:
个人报告:用雷达图展示各维度得分,标注 “待提升项” 并推荐学习资源
团队报告:统计团队整体的能力短板,如 “35% 的代表对医保政策解读不熟练”,为集体培训提供方向。
(部分素材来自于互联网,如有侵权请联系删除)





